[C++] 배열
배열
배열(Array)은 동일한 자료형의 여러 변수들을 연속된 메모리 공간에 순차적으로 저장한 데이터 모음입니다.
배열을 사용하는 경우의 예시를 들어보겠습니다.
5명의 학생의 성적을 저장하여 처리하려 할 때 배열을 사용하지 않는다면 일반 변수 5개를 다음과 같이 선언해야 합니다.
int score_0, score_1, score_2, score_3, score_4;
만약 100명의 학생 성적을 저장해야 한다면 일반 변수 100개를 선언해야 하고, 1000명의 학생 성적은 일반 변수 1000개를 해야합니다.
서로 다른 이름을 가진 1000개의 개별적인 일반 변수를 선언하는 것은 비효율적이고 프로그램의 가독성을 떨어뜨리기에 이런 경우 배열을 사용하게 됩니다.
동일한 자료형의 의미가 같은 데이터를 원하는 개수 만큼 저장할 수 있는 메모리 공간을 한번에 할당할 수 있다면 앞에서 살펴본 문제점을 해결할 수 있습니다.
이런 요구사항에 한번의 선언으로 복수의 저장공간을 효과적으로 할당하기 위해 생긴게 배열(array)입니다.
배열 선언 후 할당된 배열의 저장공간에 저장된 여러 데이터 중 특정 데이터를 참조하기 위해서는 개별 데이터의 저장 공간을 식별할 수 있어야 합니다.
저장된 각각의 데이터들은 인덱스(index)를 사용해 구분합니다.
인덱스를 통해 데이터를 파악하고 접근하며, 접근한 데이터를 각각의 값을 요소(Element)라고 합니다.
배열은 $O(1)$의 조회시간을 가진다는 장점이 있습니다.
삽입과 삭제의 경우 배열의 끝에서 작업하고, 재할당이 필요 없는 경우 $O(1)$입니다.
하지만 재할당이 필요하거나 배열의 끝이 아닌 다른 곳에서 원소를 삽입 혹은 삭제 할 경우 $O(N)$입니다.
정렬은 어떤 정렬 알고리즘을 사용하느냐에 따라 시간 복잡도가 다르게 나옵니다.
검색의 경우 일반적으로 O(N)이지만 정렬된 배열의 경우 이진 검색을 사용하면 $O(log N)$입니다.
배열 선언
배열 선언을 통해 배열 요소의 개수와 요소의 자료형을 함께 선언해야 합니다.
변수의 선언과 같이 자료형이 먼저 지정되어야하며, 그 후 배열 이름과 자료형의 저장공간 개수(배열의 크기)를 명시하기 위해 대괄호[]를 이용합니다.
자료형 배열이름[크기];
int score[5];
배열을 선언하면 메모리에 지정한 갯수만큼 저장공간을 메모리에 연속적으로 할당합니다.
score는 배열의 이름이며 연속적으로 할당된 메모리 저장공간의 시작주소를 의미합니다.
대괄호는 선언하는 변수가 배열이라는 것을 명시하며 대괄호 안에 할당할 저장공간의 크기를 규정합니다.
배열의 크기는 반드시 0보다 큰 정수형 상수로 컴파일 타임 상수가 필요합니다.
배열의 초기화
배열을 선언만하고 초기화하지 않으면 쓰레기값이 들어있습니다.
선언과 동시에 저장공간을 초기화하는 것은 다음과 같습니다.
int score[5]{ 10, 20, 30, 40, 50 }; // 순서대로 10 ~ 50까지 값으로 배열 변수를 초기화합니다.
int score[5]{ 10, 20, 30 }; // 나머지 요소의 값은 기본값(0)으로 초기화됩니다.
int score[5]{}; // 요소의 값을 지정하지 않고 유니폼 초기화를 사용하면 기본값(0)으로 초기화 합니다.
int score[]{ 10, 20, 30, 40}; // 크기를 지정하지 않았지만 초기화식의 배열 개수만큼 배열 변수를 정의해 줍니다. 즉 크기는 4입니다.
이때 각 요소는 동일한 타입이어야 하며, 컴파일 시점에 타입이 결정됩니다.
C++에서는 이빨빠진 배열(Sparse Array)을 직접 지원하지 않습니다.
배열의 인덱스
배열을 사용하기위해 앞서 이야기했던 인덱스라는 개념을 알아야합니다.
배열의 이름으로 저장된 각각의 데이터에 접근하기 위해서는 데이터의 저장 위치를 알아야 합니다.
이 위치를 알기위해 배열의 이름 자체는 배열의 시작 주소로 되어있고, 이 주소로부터 얼만큼 떨어져 있는지 헤아리는 방법을 인덱싱(Indexing)이라 하며 연산자[]로 사용합니다.
이때 배열의 이름에 해당하는 주소부터 인덱스가 0으로 시작합니다.
즉 배열의 첫 번째 요소는 인덱스가 0이며, 두 번째 요소는 인덱스가 1, 세 번째 요소는 인덱스가 2입니다.
이런 방법으로 인덱스는 1씩 증가하게 됩니다.
인덱스의 최대 값은 배열크기-1이며, 위 예시의 배열 변수score의 경우 최대 인덱스 값은4입니다.
인덱스를 이용해 배열의 요소에 접근하는 방법은 다음과 같습니다.
int score[5]{ 10, 20, 30, 40, 50 };
std::cout << score[3] << std::endl; // 배열의 3번째 요소인 30이 출력됩니다.
배열의 모든 요소에 접근하는 경우 반복문을 사용할 수 있습니다.
for문 또는 while 반복문을 사용해 인덱스로 사용하는 변수의 값을 1씩 증가시키며 배열의 요소에 접근할 수 있습니다.
int score[5]{ 10, 20, 30, 40, 50 };
for (int i = 0; i < 5; ++i)
{
std::cout << score[i] << std::endl; // 반복문이 실행되며 i 변수의 값에 따라 각 요소가 출력됩니다.
}
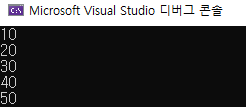
위와 같은 방법으로 인덱스를 사용해 요소에 접근했는데 만약 배열의 크기보다 큰 인덱스 값을 사용한다면 다음과 같은 일이 생깁니다.
#include <iostream>
int main()
{
int score[5]{ 10, 20, 30, 40, 50 };
for (int i = 0; i < 6; i++)
{
std::cout << score[i] << std::endl;
}
}
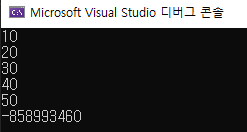
이런 일이 생긴 이유는 배열은 여러 변수들이 연속된 메모리 공간에 순차적으로 저장한 데이터 모음이지만 C++ 컴파일러에서 배열의 크기는 신경쓰지 않기 때문입니다.
배열이 인덱스를 사용해 요소에 접근하는 방법이 다음과 같기에 생기는 문제입니다.
- 배열의 시작 주소에서 자료형의 크기만큼 메모리를 읽습니다. 이것이 score[0]가 됩니다.
score[1]에 접근하기 위해서는 시작 주소에서 자료형의 크기와 인덱스를 곱한 수만큼 메모리를 넘어가고 다시 자료형의 크기만큼 메모리를 읽습니다.- 만약
score[6]처럼 배열의 크기를 벗어난 인덱스라고 해도 똑같이 자료형의 크기와 인덱스를 곱한 수만큼 메모리를 넘어가고 그 위치에서 자료형의 크기만큼 메모리를 읽습니다.
위의 방법을 좀더 쉽게 이해하기위해 메모리 주소를 보며 얘기해보겠습니다.
지금 배열의 예시로 들면 다음과 같습니다.
#include <iostream>
int main()
{
int score[5]{ 10, 20, 30, 40, 50 };
for (int i = 0; i < 6; i++)
{
std::cout << &score[i] << std::endl;
}
}
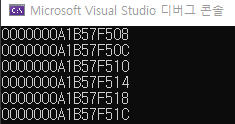
위의 이미지는 각 배열의 주소입니다.
score배열의 시작 주소는 0000000A1B57F508입니다.
score배열의 socre[1]일 때 주소는 0000000A1B57F50C입니다.
score배열의 socre[2]일 때 주소는 0000000A1B57F510입니다.
score배열의 배열 크기를 넘어선 socre[6]일 때 주소는 0000000A1B57F51C입니다.
위의 코드로 모든 배열의 주소가 4byte씩 떨어져있다는걸 알 수 있습니다.
일정한 크기로 배열이 떨어져있는 이유는 int의 크기인 4byte씩 메모리를 가지고 연속적으로 붙어있기 때문입니다.
만약 int가 아닌 bool이라면 1byte씩 떨어져 있을것입니다.
이처럼 연속된 메모리 공간을 가지고 있고, 이 연속된 메모리 공간에 접근하는 방법으로 인덱스와 자료형의 크기가 곱해진 값을 시작 주소로부터 더해 해당 인덱스의 요소에 접근했습니다.
socre배열의 3번째 요소에 접근한다면 자료형의 크기인 4 그리고 3번째 요소이므로 인덱스 2를 곱한 8라는 값이 나올겁니다.
이 값을 시작 주소(0000000A1B57F508)로부터 더하면 3번째 요소(0000000A1B57F510)에 접근합니다.
하지만 socre[6]은 우리가 만든 배열의 크기를 벗어났지만, 문법에는 문제가 없으므로 빌드와 실행이 문제없이 됐습니다.
하지만 벗어난 곳의 메모리는 우리가 관리하지 않는 곳이었고, 우리가 값을 초기화하지 않았습니다 그렇기에 알 수 없는 값인 쓰레기 값이 들어있습니다.
이런 코드는 socre배열에서 크기가 벗어난 메모리이므로 다른 변수에서 socre[6]의 메모리를 사용하고 있을 수 있습니다.
그렇기에 굉장히 위험한 코드이므로 이런 크기가 벗어난 배열의 접근을 하지 않게 주의해야 합니다.
함수 매개변수의 배열
함수에서 매개변수로 배열이 사용되면 배열의 초기화와 같은 방식으로 전달 받습니다.
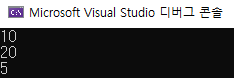
이것은 배열의 주소를 전달하는 것이고, 얕은 복사가 일어나 전달 받은 배열에서 요소에 접근해 값을 수정하면 전달한 배열에서도 값의 수정이 일어납니다.
#include <iostream>
using namespace std;
void func(int func_arr[])
{
func_arr[2] = 5;
}
int main()
{
int score[5]{ 10, 20, 30, 40, 50 };
func(score);
for (int i = 0; i < 3; i++)
{
std::cout << score[i] << std::endl;
}
}
다차원 배열
일상 생활의 데이터중 이미지, 동영상, 문서 내의 테이블, 엑셀파일의 워크시트와 같이 2차원, 3차원의 데이터가 있습니다.
이런 데이터를 컴퓨터에서 처리할 경우 프로그래머가 처리하려는 데이터의 차원을 고려해 메모리에 저장 할 수 있습니다.
배열을 가진 배열이라는 개념으로 배열 뒤에 다시 배열을 붙여서 다음과 같이 선언합니다.
int multiarray[2][3];
[행][열]과 같은 개념으로 생각하고 지정해주면 됩니다.
초기값은 행/열 순으로 기입합니다.
중괄호로 하나의 행을 묶어서 표기하고, 쉼표로 구분해서 열을 표기합니다.
다음은 2차원 배열의 초기화 예시입니다.
int multiarray[3][5] =
{
{ 0, 0, 1, 0, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 1, 1, 1, 1 }
};
다차원 배열은 2차원 배열 말고도 3차원, 4차원 등 차원의 개수를 늘릴 수 있습니다.
2차원 배열에서 모든 요소에 접근하는 반복문은 다음과 같습니다.
#include <iostream>
int main()
{
int multiarray[3][5] =
{
{ 0, 0, 1, 0, 0 },
{ 0, 1, 1, 1, 0 },
{ 1, 1, 1, 1, 1 }
};
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 5; ++j)
{
std::cout << multiarray[i][j] << ", ";
}
std::cout << std::endl;
}
}
배열을 가진 배열이므로 인덱스가 2개가 필요합니다.
그렇기에 모든 요소에 접근하고자 한다면 반복문이 2개가 필요합니다.
댓글남기기