[C++ Data Structure] Hash Table
Hash Table
해시 테이블(Hash Table)은 키(Key)와 값(Value)을 저장하는 자료구조로, 해시 함수를 사용하여 키를 특정한 인덱스로 변환한 후 해당 위치에 값을 저장하는 방식으로 동작합니다.
- 장점
- 평균적으로 $O(1)$의 시간 복잡도로 검색, 삽입, 삭제가 가능
- 정렬이 필요하지 않은 경우 리스트보다 효율적
- 단점
- 해시 함수가 좋지 않으면 충돌이 많아져 성능이 $O(n)$까지 떨어질 수 있음
- 메모리를 많이 사용할 수 있음
Hash Function
해시 함수(Hash Function)키를 입력받아 특정한 규칙에 따라 변환하여 배열의 인덱스를 생성하는 함수입니다.
해시 함수의 역할
- 키를 일정한 범위의 숫자로 변환합니다.
- 변환된 숫자를 해시 테이블의 크기에 맞게 조정하여 인덱스로 변환합니다.
- 해당 인덱스에 데이터를 저장합니다.
해시 함수가 잘 동작을 하기 위해서 만족해야하는 조건들은 다음과 같습니다.
- 입력 데이터의 크기가 달라도 결과 값이 일정한 범위를 유지해야 함 (테이블 크기 내에서 유지)
- 동일한 입력에 대해 항상 동일한 출력
- 해시 함수는 시간 복잡도를 $O(1)$로 매우 빠르게 연산이 필수
- 충돌(Collision)이 적게 발생해야 함
1번 속성은 예를 들어, SHA-256 해시 함수는 입력이 아무리 크더라도 256비트(32바이트) 길이의 해시 값을 반환합니다.
2번 속성을 결정성(Deterministic)이라고 부릅니다.
해시 함수의 결정성은 동일한 입력값에 대해 항상 동일한 해시값을 출력하는 특성을 의미합니다.
해시 함수의 신뢰성과 일관성을 보장하는 중요한 특성입니다.

Image from Wikimedia Commons
해시 함수의 종류
나눗셈법
키를 소수(prime number)로 나누고 나머지를 인덱스로 사용하는 방법
간단하지만, 테이블 크기를 신중하게 설정해야 합니다.
특정 패턴 키(예: 연속된 숫자)가 있을 경우 충돌이 쉽게 발생할 수 있습니다.
$h(x) = x \mod m$
($m$은 소수)
int hashFunction(int key, int tableSize)
{
return key % tableSize;
}
곱셈법
나눗셈법과 유사하지만 충돌이 적고, 소수를 찾을 필요가 없습니다.
$h(x) = \lfloor (m \times (A \times x \mod 1)) \rfloor$
(A는 0과 1 사이의 상수, 보통 황금비 0.618 사용)
const double A = 0.6180339887; // (골든 레이시오의 역수)
int multiplicationHash(int key, int tableSize)
{
double temp = key * A;
double fractionalPart = temp - floor(temp); // 소수 부분 추출
return (int)(tableSize * fractionalPart); // 테이블 크기와 곱하여 정수 인덱스 생성
}
문자열 해싱
아스키 코드 기반 해싱
문자열을 숫자로 변환하여 해시 값을 생성하는 방법입니다.
각 문자의 ASCII 값을 더한 후, 모듈러 연산을 수행합니다.
같은 문자 조합(“abc”와 “bca”)이 있으면 충돌이 쉽게 발생합니다.
$h(s) = (s[0] + s[1] + s[2] + \cdots + s[n−1]) \mod m$
int stringHashFunction(string key, int tableSize)
{
int hashValue = 0;
for (char c : key)
{
hashValue += c;
}
return hashValue % tableSize;
}
가중치 적용 해싱 (Polynomial Rolling Hash)
문자열을 숫자로 변환 후 문자의 위치에 따라 가중치를 다르게 부여하는 해싱입니다.
소수를 사용하여 충돌을 줄이는 효과가 있습니다.
$hash(s) = (s[0] + s[1] * p + s[2] * p^2 + … + s[n-1] * p^{(n-1)}) \mod m$
보통 $p$는 $31$, $m$은 매우 큰 소수 사용
int polynomialRollingHash(string key, int tableSize)
{
long long hashValue = 0;
long long p = 31; // 작은 소수(Prime Number)
long long power = 1;
for (char c : key)
{
hashValue = (hashValue + (c - 'a' + 1) * power) % tableSize;
power = (power * p) % tableSize;
}
return (int)hashValue;
}
Hash Collision
해시 충돌(Hash Collision)이란 두 개 이상의 서로 다른 입력값(키)이 동일한 해시 값을 가질 때 발생하는 현상입니다.
해시 함수가 유한한 크기의 값(해시 테이블 크기 $m$)으로 무한한 입력을 매핑하기 때문에 불가피하게 발생하는 문제입니다.
해시 테이블 크기가 100이면 101개의 서로 다른 키가 존재할 경우, 최소한 2개는 같은 해시 값이 됩니다. (비둘기집 원리)
해시 함수가 데이터를 고르게 분포시키지 못하면 특정 값에 집중적으로 충돌이 발생할 수 있습니다.
단순하게 $h(x) = x \mod 10$ 같은 함수를 사용하면, 10의 배수 간 충돌이 발생합니다.
테이블 크기가 소수가 아닐 경우 특정 패턴이 반복될 가능성이 높아 충돌 발생 가능성이 증가합니다.
$m = 100$이면 100의 약수(예: 2, 4, 5, 10)의 배수들에서 충돌이 발생합니다.
Chaining
체이닝(Chaining)은 같은 해시 값을 가진 데이터를 연결 리스트(Linked List)로 저장합니다.
해시 테이블의 각 슬롯이 연결 리스트를 포합니다.
충돌이 발생하면 해당 슬롯의 리스트에 새 요소 추가합니다.
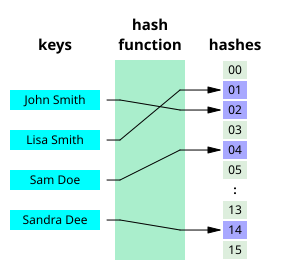
Image from Wikimedia Commons
해시 테이블 크기에 관계없이 모든 데이터를 저장 가능해집니다.
하지만, 리스트가 길어지면 탐색 속도가 느려질 수 있습니다.
C++ unordered_map은 기본적으로 체이닝을 사용합니다.
Open Addressing
개방 주소법(Open Addressing)은 충돌이 발생하면 새로운 빈 슬롯을 찾아 데이터를 저장합니다.
종류는 다음과 같습니다.
- 선형 탐사(Linear Probing): 충돌 발생 시 순차적으로 다음 빈 슬롯을 탐색
- $h(x, i) = (h(x) + i) \mod m$
- 클러스터링(Clustering, 특정 영역에 데이터가 몰리는 현상) 발생 가능
- 충돌 많으면 느림
- 이차 탐사(Quadratic Probing): 충돌 발생 시 제곱수 단위(1, 4, 9, 16, …)로 탐색
- $h(x, i) = (h(x) + i^2) \mod m$
- 클러스터링 문제가 낮지만, Secondary Clustering 발생 가능
- 선형 탐사보다 빠름
- 이중 해싱(Double Hashing): 충돌 발생 시 다른 해시 함수를 한 번 더 적용하여 탐색
- $h(x, i) = (h_1(x) + i \times h_2(x)) \mod m$
- 이중 해싱은 충돌이 많아도 해시 함수가 균등한 탐색을 제공
- 가장 균일한 성능
댓글남기기